Spark3.x Journey of Discovery | Spark 2.4 to 3.4 releases notes on spark core and SQL
张晓龙 / 2023-05-04
- 👉 Spark3.x Journey of Discovery | Spark3.x 主节点 Master 和 Worker 节点 启动过程分析
- 👉 Spark3.x Journey of Discovery | Spark RPC 架构设计和Akka架构以及基于Spark RPC框架的通信代码演示
- 👉 Spark3.x Journey of Discovery | Spark 2.4 to 3.4 releases notes on spark core and SQL
- 👉 Spark3.x Journey of Discovery | Spark RPC 框架的发展历史和RPC核心类图关系
- 👉 Spark3.x Journey of Discovery | Spark 基础&重要的概念(base and important conception)
- 👉 Spark3.x Journey of Discovery | Spark3.x 新特性 AQE的理解和介绍
- 👉 Spark3.x Journey of Discovery | Kyuubi1.7 Overview和部署核心参数调优
The Discovery of Spark 系列文章目前共:7 篇
将我比较关心部分放到这里,如果需要更多的内容,可以到 spark release notes 查看更多!
Spark2 to Spark3.0
spark3.0, The vote passed on the 10th of June, 2020.
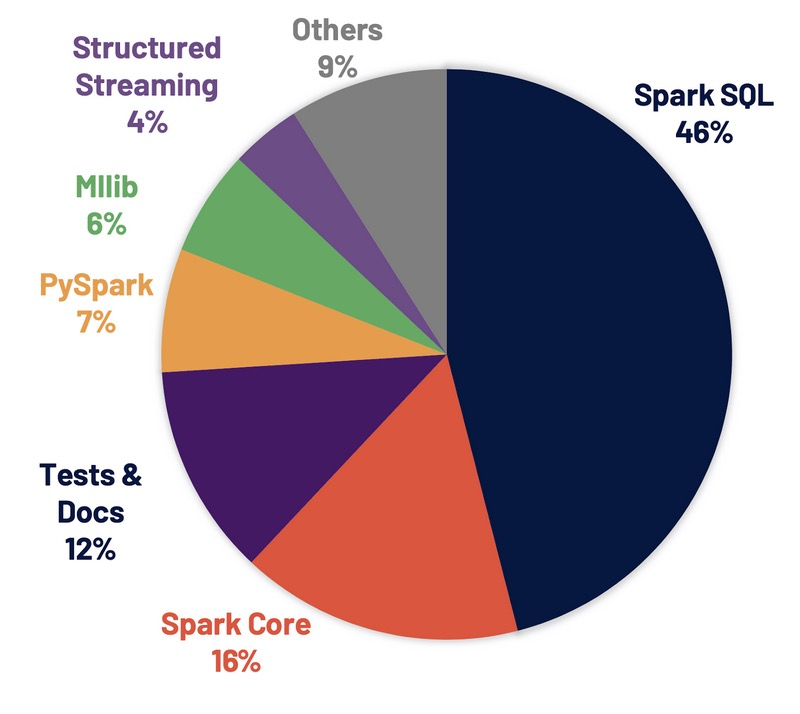
Spark SQL is the top active component in this release. 46% of the resolved tickets are for Spark SQL.
These enhancements benefit all the higher-level libraries, including structured streaming and MLlib, and higher level APIs, including SQL and DataFrames. Various related optimizations are added in this release.
In TPC-DS 30TB benchmark, Spark 3.0 is roughly two times faster than Spark 2.4.
The biggest new features in Spark 3.0
- 2x performance improvement on TPC-DS over Spark 2.4, enabled by adaptive query execution, dynamic partition pruning and other optimizations
- ANSI SQL compliance
- Significant improvements in pandas APIs, including Python type hints and additional pandas UDFs
- Better Python error handling, simplifying PySpark exceptions
- New UI for structured streaming
- Up to 40x speedups for calling R user-defined functions
- Over 3,400 Jira tickets resolved
To Spark3.1
This release adds Python type annotations and Python dependency management support as part of Project Zen.
Other major updates include improved ANSI SQL compliance support, history server support in structured streaming, the general availability (GA) of Kubernetes and node decommissioning in Kubernetes and Standalone.
Highlights in Spark3.1
- Unify create table SQL syntax (SPARK-31257)
- Shuffled hash join improvement (SPARK-32461)
- Experimental node decommissioning for Kubernates and Standalone (SPARK-20624)
- Enhanced subexpression elimination (SPARK-33092, SPARK-33337, SPARK-33427, SPARK-33540)
- Kubernetes GA (SPARK-33005)
- Use Apache Hadoop 3.2.0 by default (SPARK-32058, SPARK-32841)
To Spark3.2 — now, we use spark3.2.1 in our company
Spark supports the Pandas API layer on Spark.
Other major updates include RocksDB StateStore support, session window support, push-based shuffle support, ANSI SQL INTERVAL types, enabling Adaptive Query Execution (AQE) by default, and ANSI SQL mode GA.
Highlights in Spark3.2
- Support Pandas API layer on PySpark (SPARK-34849)
- Enable adaptive query execution by default (SPARK-33679)
- Support push-based shuffle to improve shuffle efficiency (SPARK-30602)
- Add RocksDB StateStore implementation (SPARK-34198)
- EventTime based sessionization (session window) (SPARK-10816)
- ANSI SQL mode GA (SPARK-35030)
- Support for ANSI SQL INTERVAL types (SPARK-27790)
- Query compilation latency reduction (SPARK-35042, SPARK-35103, SPARK-34989)
- Support Scala 2.13 (SPARK-34218)
To Spark3.3
This release improve join query performance via Bloom filters, increases the Pandas API coverage with the support of popular Pandas features.
Simplifies the migration from traditional data warehouses by improving ANSI compliance and supporting dozens of new built-in functions, boosts development productivity with better error handling, autocompletion, performance, and profiling.
Highlights in Spark3.3
- Row-level Runtime Filtering (SPARK-32268)
- ANSI enhancements (SPARK-38860)
- Error Message Improvements (SPARK-38781)
- Support complex types for Parquet vectorized reader (SPARK-34863)
- Hidden File Metadata Support for Spark SQL (SPARK-37273)
- Provide a profiler for Python/Pandas UDFs (SPARK-37443)
- Introduce Trigger.AvailableNow for running streaming queries like Trigger.Once in multiple batches (SPARK-36533)
- More comprehensive DS V2 push down capabilities (SPARK-38788)
- Executor Rolling in Kubernetes environment (SPARK-37810)
- Support Customized Kubernetes Schedulers ( SPARK-36057)
- Migrating from log4j 1 to log4j 2 (SPARK-37814)
To Spark3.4(Apr 13, 2023)
This release introduces Python client for Spark Connect, augments Structured Streaming with async progress tracking and Python arbitrary stateful processing, increases Pandas API coverage and provides NumPy input support, simplifies the migration from traditional data warehouses by improving ANSI compliance and implementing dozens of new built-in functions, and boosts development productivity and debuggability with memory profiling.
Highlights in Spark3.4
- Python client for Spark Connect (SPARK-39375)
- Implement support for DEFAULT values for columns in tables (SPARK-38334)
- Support TIMESTAMP WITHOUT TIMEZONE data type (SPARK-35662)
- Support “Lateral Column Alias References” (SPARK-27561)
- Harden SQLSTATE usage for error classes (SPARK-41994)
- Enable Bloom filter Joins by default (SPARK-38841)
- Better Spark UI scalability and Driver stability for large applications (SPARK-41053)
- Async Progress Tracking in Structured Streaming (SPARK-39591)
- Python Arbitrary Stateful Processing in Structured Streaming (SPARK-40434)
- Pandas API coverage improvements (SPARK-42882) and NumPy input support in PySpark (SPARK-39405)
- Provide a memory profiler for PySpark user-defined functions (SPARK-40281)
- Implement PyTorch Distributor (SPARK-41589)
- Publish SBOM artifacts (SPARK-41893)
- Support IPv6-only environment (SPARK-39457)
- Customized K8s Scheduler (Apache YuniKorn and Volcano) GA (SPARK-42802)