Spark3.x Journey of Discovery | Spark 基础&重要的概念(base and important conception)
张晓龙 / 2023-04-21
- 👉 Spark3.x Journey of Discovery | Spark RPC 架构设计和Akka架构以及基于Spark RPC框架的通信代码演示
- 👉 Spark3.x Journey of Discovery | Spark RPC 框架的发展历史和RPC核心类图关系
- 👉 Spark3.x Journey of Discovery | Kyuubi1.7 Overview和部署核心参数调优
The Discovery of Spark 系列文章目前共:3 篇
"系统性分析的一种方法是将系统拆解为原子部分,再分析原子部分之间的关系,通过原子部分和关系来定义系统。"
通过学习和理解 spark 的基本的概念,以及关系组合影响,让我们更好的理解 spark 整个逻辑体系和生态。
利用最近火热的 ChatGPT 老师来给我一个起点,来讲讲 saprk 的基本概念以及关系。
Here are some key concepts in Apache Spark:
1. Spark Context: The entry point of any Spark application is the SparkContext. It represents the connection to the Spark Cluster and is responsible for coordinating all processes that run within that cluster.
2. RDD: RDD stands for Resilient Distributed Datasets. It is the fundamental data structure in Spark applications that represents distributed collections of objects.
3. Transformation: Transformations take an RDD and produce a new RDD. RDDs are immutable and any transformations applied to them generate a new RDD.
4. Action: Actions are operations that trigger the computation on the data. Transformations don't trigger computation until an action is invoked.
5. DAG: The transformation of RDDs result in a Directed Acyclic Graph (DAG) of computations. This DAG is responsible for the efficient scheduling of tasks.
6. Job: A job is a sequence of tasks that are executed on the data.
7. Stage: A stage is a collection of tasks that can be executed in parallel.
8. Partition: A partition is a logical division of an RDD.
9. Executors: Executors are the processes that run on worker nodes and execute user code.
10. Shuffle: A shuffle is the process of redistributing data between the partitions during a job execution.
接下来以上面的为起点,进行 spark 基础概念的解释。
1、Spark Context & SparkSession
现在源码中看下这个 SparkContext 的注释定义,
/**
* Main entry point for Spark functionality. A SparkContext represents the connection to a Spark
* cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
*
* @note Only one `SparkContext` should be active per JVM. You must `stop()` the
* active `SparkContext` before creating a new one.
* @param config a Spark Config object describing the application configuration. Any settings in
* this config overrides the default configs as well as system properties.
*/
在 spark2.0 版本之前,SparkContext 是提交和管理 spark 任务的入口类。 用于创建 RDD、accumulate和 broadcast 变量等。 在 saprk2.0 版本之后,SparkSession 成为重要的入口,用于操作 RDD、Dataframe、DataSet。 不过 SparkSession 还没有完全替代SparkContext
 Figure 1: Source spark.apache.org
Figure 1: Source spark.apache.org
Spark Session 在不同的 contexts 中具备了所有可用的 API,
- SparkContext
- SQLContext
- StreamingContext
- HiveContext
通过SparkSession.builder()、SparkSession.newSession()可以创建多个 SparkSession,这个不同于只能存在一个的 SparkContext。
2、RDD
Spark RDD (Resilient Distributed Dataset),是 spark 基本的数据结构,以及数据抽象单元。
RDD 特点
- In-Memory Processing – Immutability – Fault Tolerance – Lazy Evolution – Partitioning – Parallelize
 Figure 2: Spark RDD 结构
Figure 2: Spark RDD 结构
用 RDDs 和分布式共享内存系统(Distributed shared memory 即 DSM)进行对比理解
| Aspect(概念) | RDDs | Distribute shared memory(分布式共享内存) |
|---|---|---|
| Reads | 粗粒度或者细粒度 | 细粒度 |
| Writes | 粗粒度 | 细粒度 |
| 数据一致性 | 不重要的(因为RDD是不可变的) | 取决于app 或者 runtime |
| 容错 | 利用lineage达到细粒度且低延迟的容错 | 需要应用checkpoints(就是需要写磁盘)并且需要程序回滚 |
| 计算慢的任务 | 可以利用备份的任务来解决 | 很难做到 |
| 计算数据的位置 | 自动的机遇数据本地性 | 取决于app(runtime是以透明为目标的) |
| 内存不足时的行为 | 和已经存在的数据流处理系统一样,写磁盘 | 非常糟糕的性能(需要内存的交换?) |
有两种方式创建 RDD,
- parallelizing an existing collection
- referencing a dataset in an external storage system
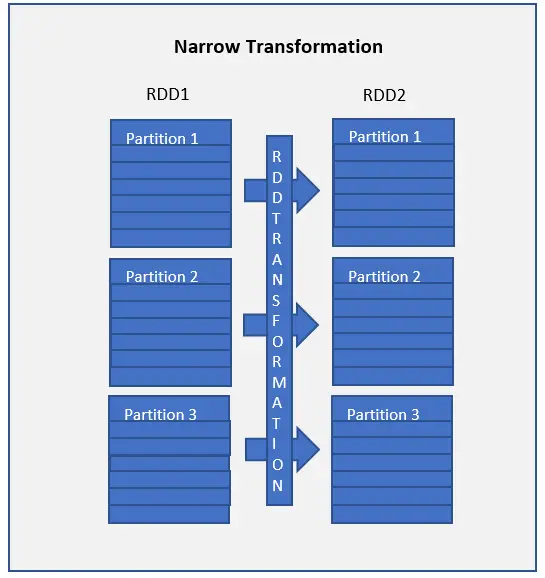
RDD Transformation 类型
- Narrow Transformation(窄依赖) – map(), mapPartition(), flatMap(), filter(), union() 等
- Wider Transformation(宽依赖) – groupByKey(), aggregateByKey(), aggregate(), join(), repartition() 等等

3、Transformation
作用于 RDD 上的各种操作,生成一个或者多个新的 RDD。

RDD Transformations 是一个延迟执行的操作,遇到 action 操作才会真正执行。
宽窄Transformations 在第 2 大点 RDD 中有介绍
4、Action
RDD action 是一类操作,用于触发生成新的 RDD
列举一些 case

5、DAG
DAG 是有向无环图,一般用来描述任务之间的先后关系, Spark 中的 DAG 就是 RDD 内部的转换关系,这些转换关系会被转换成依赖关系,进而被划分 成不同阶段,从而描绘出任务的先后顺序。
DAG 执行引擎的显著优点:
1、提高 Scheduler 的调度效率(多个没关系的stage的调度可以并行执行)
2、支持基于 Linage 的 Fault Tolerance
3、有向无环,无循环依赖
4、减少中间结果的落盘和读取操作次数从而提高任务执行效率,mapreduce性能差的原因就在于执行过程中的任何的shuffle read和write都是基于磁盘。 Spark 提供了基于内存的存储体系功能的支撑:支持我们把数据持久化到内存,方便下一个阶段的Task来获取
DAG 和 RDD、JOB、Stage 的关系
1、RDD学名:弹性分布式数据集,是一个容错的并行的数据结构,可以控制将数据存储到磁盘或内存,能够获取数据的分区等,RDD还提供了一堆用于计算的类似于 Scala函数的高阶操作算子用于完成计算。
2、RDD按照依赖关系,会构建成有向无环图,既DAG,RDD之间的关系有两种:NarrowDependecy和ShuffleDependency,NarrowDependecy会被划分到同一 一个Stage中,以管道的方式迭代执行。ShuffleDependency 由于所依赖的 分区Task 不止上游一个 Task,往往需要跨节点传输。
3、RDD本身是一个不可变的分布式数据集,NarrowDependecy只需要重新执行父RDD的丢失分区的计算既可以恢复,但是ShuffleDependecy则需要考虑恢复所 有父RDD的丢失分区。失败的Task重新执行,执行成功的Task不执行,从Checkpoint中进行读取即可。
4、RDD分区,由于RDD是一个分布式集合,则可以进行并行计算提高效率。RDD的分区可以根据业务需求和硬件资源来进行并行任务的数量的控制,从而提高任务的 执行效率。
5、Spark的Application会按照ShuffleDependency划分成多个Stage,最后一个Stage称之为ResultStage,前面的Stage称之为ShuffleStage,Stage 和Stage之间,需要进行数据Shuffle操作,可能导致数据倾斜。
6、一个stage中到底有多少个task: 由当前这个stage的最后一个RDD的分区个数来决定
DAG 逻辑关系
DAGScheduler 负责把 构建出来的
DAG 切分成多个stage
标准:shffle算子 ShuffleDenpedency
RDD与RDD之间的转换关系依赖:
宽依赖 ShuffleDenpedency
窄依赖 NarrowDependency
Stage 逻辑关系 一个stage中,其实可能包含多个RDD,和多个计算逻辑, 上下RDD之间的依赖关系就只是普通的一一对应的关系,RDD与RDD之间就是窄依赖 在一个stage之间,所有的RDD的依赖都是窄依赖。 上一个stage的最后一个 RDD 和下一个stage的第一个RDD之间是宽依赖
6、Job & stage
官方给的一些定义
| Term | Meaning |
|---|---|
| Application | 用户编写的Spark应用程序,包括一个Driver和多个executors |
| Application | jar 包含用户程序的Jar包 |
| Driver | Program 运行main()函数并创建SparkContext进程 |
| worker | node 集群中可以运行程序代码的节点(机器) |
| Executor | 运行在worker node上执行具体的计算任务,存储数据的进程 |
| Task | 被分配到一个Executor上的计算单元 |
| Job | 由多个任务组成的并行计算阶段,因RDD的Action产生 |
| Stage | 每个Job被分为小的计算任务组,每组称为一个stage |

7、Partition
通常一个RDD被划分为一个或多个Partition,Partition是Spark进行数据处理的基本单位,一般来说一个Partition对应一个Task,而一个Partition中通常包含数据集中的多条记录(Record)。 注意不同Partition中包含的记录数可能不同。Partition的数目可以在创建RDD时指定,也可以通过reparation和coalesce等算子重新进行划分。

8、Master & Workers / Driver & Executors
master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用。
worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
driver进程就是应用的main()函数并且构建sparkContext对象,当提交应用之后,便会启动一个对应的driver进程,driver本身会根据设置的参数占有一定的资源(主要指cpu core和memory)。
executor进程宿主在worker节点上,一个worker可以有多个executor。每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver,每个executor执行的task都属于同一个应用。
此外executor还有一个功能就是为应用程序中要求缓存的 RDD 提供内存式存储,RDD 是直接缓存在executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
结构图可以看 Figure 1
9、Shuffle
Shuffle 是一种重新分布数据的机制策略,将在各个 executors 上的数据按照要求重新分布。
一般通过 gropByKey(), reducebyKey(), join(), groupBy() 等操作进行触发。
Spark Shuffle 是非常”昂贵“的操作,会消耗系统的以下资源
- Disk I/O
- Involves data serialization and deserialization
- Network I/O