自己动手实现推荐系统:常用推荐算法优势分析 - Build Res System by Myself
张晓龙 / 2022-03-20
本文包含两部分,一是常见算法类(部分文字摘自《推荐系统实践-项亮》),二是分析目前各个大公司放出来的推荐系统机构。
1、算法分析
简介:通过在用户的一系列行为中寻找特定模式来产生用户特殊 推荐。
算法的核心思想就是:如果 两个用户对于一些项的评分相似程度较高,那么一个用户对于一个新项的 评分很有可能类似于另一个用户。
输入:仅仅依赖于惯用数据(例如评价、购买、下载等用户偏好 行为)。
类型:
- 基于邻域的协同过滤(基于用户和基于项);
- 邻域方法(即基于内存的 CF)是使用用户 对已有项的评分直接预测该用户对新项的评分。基于邻域的 CF 方法意在找出项与项之间的联系(基于项的 CF),或 者用户与用户之间的联系(基于用户的 CF)。
- 基于用户的 CF 通过找出对项的偏好与你相似的用户从而基于他们对于新项的喜好来为你进行推荐。
- 基于项的 CF 会向用户推荐与用户喜欢的项相似的项,这种相似是基于项的共同出现几率(例如用户买了 X,通时也买了 Y)。
- 邻域方法(即基于内存的 CF)是使用用户 对已有项的评分直接预测该用户对新项的评分。基于邻域的 CF 方法意在找出项与项之间的联系(基于项的 CF),或 者用户与用户之间的联系(基于用户的 CF)。
- 基于模型的协同过滤(矩阵因子分解、受限玻尔兹曼机、贝叶斯网络等)。
- 基于模型的方 法是使用历史评分数据,基于学习出的预测模型,预测对新项的评分。基于模型的方法会在 使用评分去学习预测模型的基础上,去预测新项,一般的想法是使用机器 学习算法建立用户和项的相互作用模型,从而找出数据中的模式。贝叶斯网络、聚类、分类、回归、矩阵分解、受限玻尔兹曼机等等
- 基于邻域的协同过滤(基于用户和基于项);
优点:
- 需要最小域;
- 不需要用户和项;
- 大部分场景中能够产生足够好的结果。
缺点:
- 冷启动问题;
- 需要标准化产品;
- 需要很高的用户和项的比例(1:10);
- 流行度偏见(有长尾的时候表现不够好);
- 难于提供解释。
2、基于内容的推荐算法
简介:向用户推荐和其过去喜欢项的内容(例如元数据、描述、话题等等)相似的项。
在基于内容的推荐中,假设可以获取到 item 的描述信息, 并将其作为 item 的特征向量(例如标题、年份、描述)。这些特征向量 被用于创建一个反映用户偏好的模型。各种信息检索(例如 TF-IDF)和 机器学习技术(例如朴素贝叶斯、支持向量机、决策树等)可被用于创建 用户模型,从而为用户产生推荐。
输入:仅仅依赖于项和用户的内容/描述(除了惯用数据)。
类型:
- 信息检索(例如 tf-idf 和 Okapi BM25);
- 机器学习(例如朴素贝叶斯、支持向量机、决策树等)。
优点:
- 没有冷启动问题;
- 不需要惯用数据;
- 没有流行度偏见,可以推荐有罕见特性的项; ο 可以使用用户内容特性来提供解释。
缺点:
- 项内容必须是机器可读的和有意义的; ο 容易归档用户;
- 很难有意外,缺少多样性;
- 很难联合多个项的特性。
3、混合推荐算法
简介:综合利用协同过滤推荐算法和基于内容的推荐算法各自的 优点同时抵消各自的缺点。
输入:同时使用用户和项的内容特性与惯用数据,同时从两种输 入类型中获益。
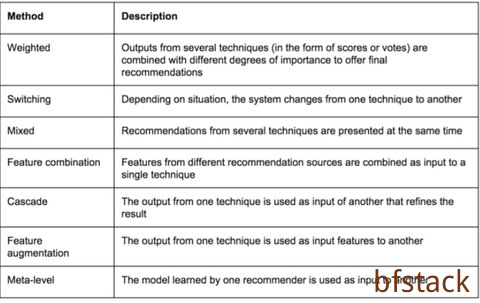
类型:
- 加权;
- 交换;
- 混合;
- 特性组合;
- 案列
- 特征增强
- 元层次
优点:
- 由于单独使用协同过滤推荐算法和基于内容的推荐算法;
- 没有冷启动问题;
- 没有流行度偏见,可推荐有罕见特性的项;
- 可产生意外,实现多样性。
缺点:
- 需要通过大量的工作才能得到正确的平衡。
4、流行度推荐算法
- 简介:这是一种推荐流行项的方法(例如最多下载、最多看过、最 大影响的项)。
- 输入:使用惯用数据和项的内容(例如类目)。
- 优点:
- 相对容易实现;
- 良好的基准算法;
- 有助于解决新用户冷启动问题。
- 缺点:
- 需要标准化产品;
- 经常需要一些项的类型进行分类;
- 不会推荐新项(很少有机会被观测到);
- 推荐列表不会改变太大。
5、高级非传统推荐算法
- 类型
- 深度学习
- 学习等级
- multi-armed bandits(探索/开发)
- 上下文感知推荐
- 张量分解
- 分解机
- 社会推荐
- 优点:
- 利于勉强维持最终性能百分点;
- 你可以说你正在使用渐进的方式。
- 缺点:
- 难于理解;
- 缺乏推荐工具支持
- 没有为你的首个推荐系统提供推荐的方式。
二、推荐系统结构实例
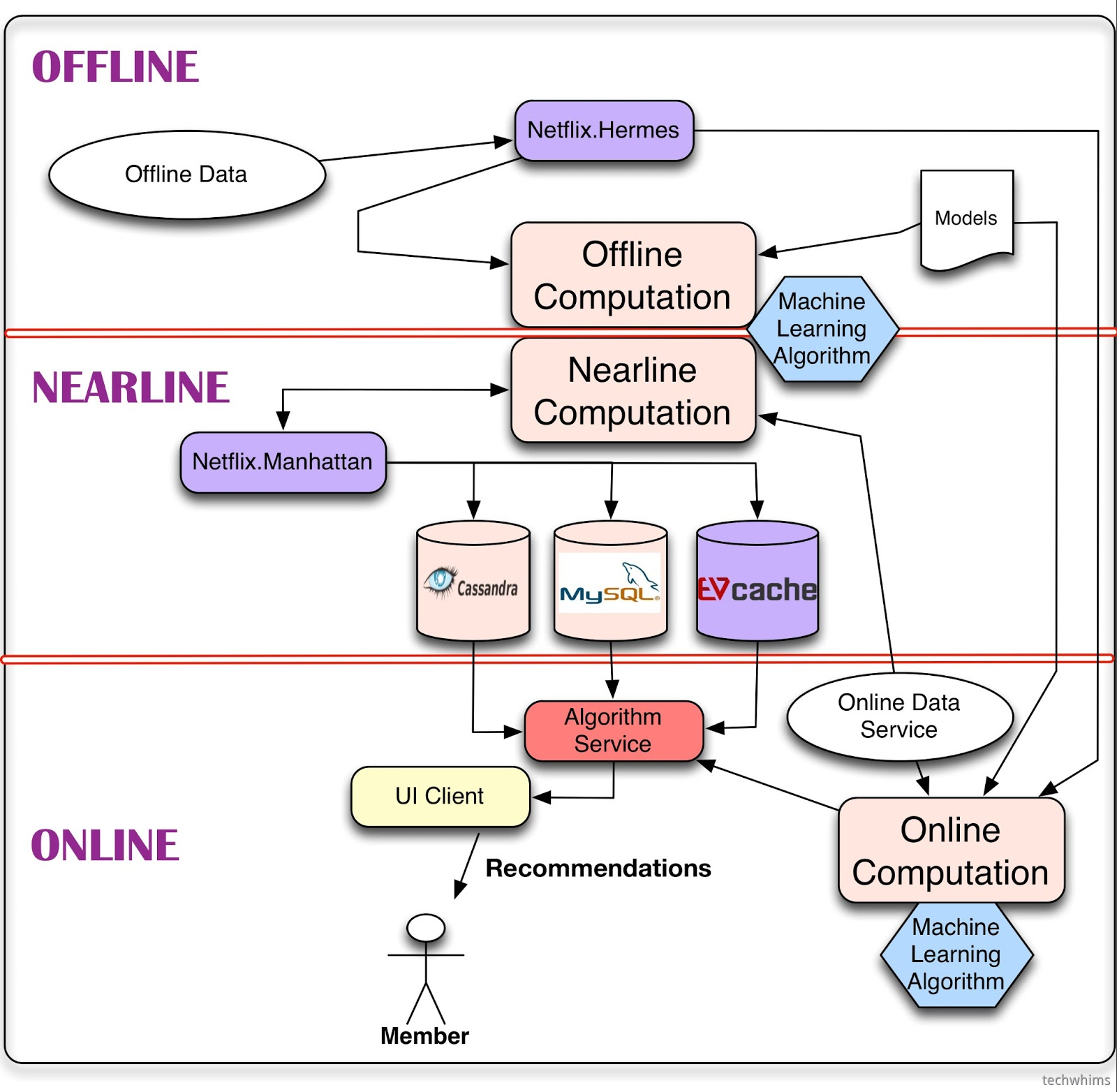
netfix
首先是大名鼎鼎的netfix
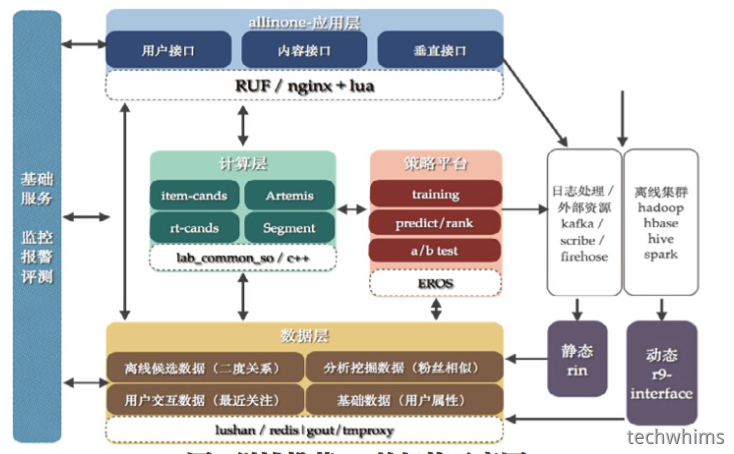
新浪微博
国内我们看一下新浪
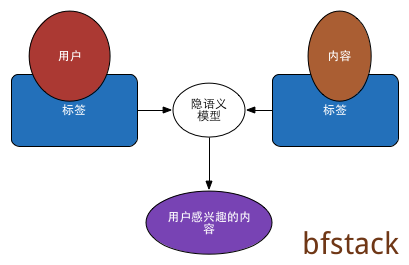
基于内容的推荐
基于内容和用户画像的个性化推荐属于基于内容的推荐。对于此种推荐,有两个实体:内容和用户,因此需要有一个联系这两者的东西,即为标签。内容转换为标签即为内容特征化,用户则称为用户特征化。对于此种推荐,主要分为以下几个关键部分:
- 标签库
- 内容特征化
- 用户特征化
- 隐语义推荐
综合上面讲述的各个部分即可实现一个基于内容和用户画像的个性化推荐系统,
(1)标签库 标签是联系用户与物品、内容以及物品、内容之间的纽带,也是反应用户兴趣的重要数据源。标签库的最终用途在于对用户进行行为、属性标记。是将其他实体转换为计算机可以理解的语言关键的一步。
标签库则是对标签进行聚合的系统,包括对标签的管理、更新等。
一般来说,标签是以层级的形式组织的。可以有一级维度、二级维度等。 标签的来源主要有:
- 已有内容的标签
- 网络抓取流行标签
- 对运营的内容进行关键词提取
对于内容的关键词提取,使用结巴分词 + TFIDF即可。此外,也可以使用TextRank来提取内容关键词。
这里需要注意的一点是对于关联标签的处理,比如用户的标签是足球,而内容的标签是德甲、英超,那么用户和内容是无法联系在一起的。最简单的方式是人工设置关联标签,此外也可以使用word2vec一类工具对标签做聚类处理,构建主题模型,将德甲、英超聚类到足球下面。 (2) 内容特征化 内容特征化即给内容打标签,目前有两种方式:人工打标签和机器自动打标签 针对机器自动打标签,需要采取机器学习的相关算法来实现,即针对一系列给定的标签,给内容选取其中匹配度最高的几个标签。这不同于通常的分类和聚类算法。可以采取使用分词 + Word2Vec来实现,过程如下:
- 将文本语料进行分词,以空格,tab隔开都可以,使用结巴分词。
- 使用word2vec训练词的相似度模型。
- 使用tfidf提取内容的关键词A,B,C。
- 遍历每一个标签,计算关键词与此标签的相似度之和。
- 取出TopN相似度最高的标签即为此内容的标签。
此外,可以使用文本主题挖掘相关技术,对内容进行特征化。这也分为两种情况:
- 通用情况下,只是为了效果优化的特征提取,那么可以使用非监督学习的主题模型算法。如LSA、PLSI和GaP模型或者LDA模型。
- 在和业务强相关时,需要在业务特定的标签体系下给内容打上适合的标签。这时候需要使用的是监督学习的主题模型。如sLDA、HSLDA等。
(3) 用户特征化 用户特征化即为用户打标签。通过用户的行为日志和一定的模型算法得到用户的每个标签的权重(泊松分布求解每个行为的权重;有监督的主题模型如SLDA;无监督的主题模型LSA)。
- 用户对内容的行为:点赞、不感兴趣、点击、浏览。对用户的反馈行为如点赞赋予权值1,不感兴趣赋予-1;对于用户的浏览行为,则可使用点击/浏览作为权值。
- 对内容发生的行为可以认为对此内容所带的标签的行为。
- 用户的兴趣是时间衰减的,即离当前时间越远的兴趣比重越低。时间衰减函数使用1/[log(t)+1], t为事件发生的时间距离当前时间的大小。
- 要考虑到热门内容会干预用户的标签,需要对热门内容进行降权。使用click/pv作为用户浏览行为权值即可达到此目的。
- 此外,还需要考虑噪声的干扰,如标题党等。
另外,非业务强相关的情况下,还可以考虑使用LSA主题模型等矩阵分解的方式对用户进行标签化。
(4) 隐语义推荐 有了内容特征和用户特征,可以使用隐语义模型进行推荐。这里可以使用其简化形式,以达到实时计算的目的。
用户对于某一个内容的兴趣度(可以认为是CTR):
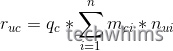
其中i=1…N是内容c具有的标签,m(ci)指的内容c和标签i的关联度(可以简单认为是1),n(ui)指的是用户u的标签i的权重值,当用户不具有此标签时n(ui)=0,q©指的是内容c的质量,可以使用点击率(click/pv)表示。
(完)