Wide & Deep learning for rec sys 阅读分析
张晓龙 / 2021-12-10
这篇《Wide & Deep Learning for Recommender Systems》论文是在2016年就已经发表出来了,通过检索相关,发现已经有一些业务在使用这个框架或者改良的版本。最近在我们的产品首页做一个课程推荐,找到了这篇论文,所以就顺手学习参考做个记录,文章分为以下两个部分:
(1) 论文阅读分析 (2) 相关知识的引入
1. 论文阅读(混合翻译和理解)
(1)背景介绍
推荐系统可以被看成一个搜索排序系统,我们之前很多的推荐就是利用搜索去做,设计一个scorer,然后rank所有候选的docs,取topK返回给用户,点击转换率也不错(需要基于对业务和场景的深入理解)。同搜索系统一样,同样面对两个问题:memorization(记忆)和 generalization(泛化) 。memorization是基于历史数据,学习到频繁同现的item或者feature,挖掘一些相关性的东西;generalization是基于上一步学习到的特性进行迁移和挖掘一些新feature(很少出现或者没有出现过的特性)。
基于memorization的推荐系统还是比较典型的,因为是基于之前准确学习到的特征进行推荐的,例如常见的CF算法,Item-CF中发现物品于物品之间的联系给用户推荐,或者基于内容(或tag)的推荐也是类似的,而generalization策略的使用,则可以提升推荐系统的迁移性(多样性),比如使用神经网络等等。
开始介绍之前,我们先预习下内容:
- 1> 先分析了下目前使用广泛的LR线性模型,由于模型比较简单、可扩展、可解释性好,所以应用比较多。LR模型通常在使用one-hot编码的二值化稀疏特征上进行训练,比如论文中关于app下载的特征,user_installed_app=netflix时,设置值为1,通过使用向量积(叉乘)转换稀疏特征之后,memorization可以设置当出现 AND(user_installed_app=netflix, impres- sion_app=pandora”)时,也设置值为1,不过,向量积(叉乘)转换不能泛化出之前没有出现过的query-item特征对。而generalization可以通过更粗粒度的特征去泛化一些新特征。
- 2> Embedding-based模型,例如FM算法、深度神经网络可以通过学习一个dense embedding vector(低纬稠密嵌入向量)去泛化出之前没有出现过的query-item特征,使用了更少的特征工程,但是,学习到一个低纬去代表一个有稀疏特征和high-rank的query和item是非常困难的,比如特殊爱好的用户或者相关的item数比较少,这些情况下当使用dense embedding去计算所有的query-items的时候,会出现很多非零的预测,就会导致推荐一些不相关的item。但是,使用向量积转换的线性模型(更少参数)是可以记住这些特殊规则的特征。
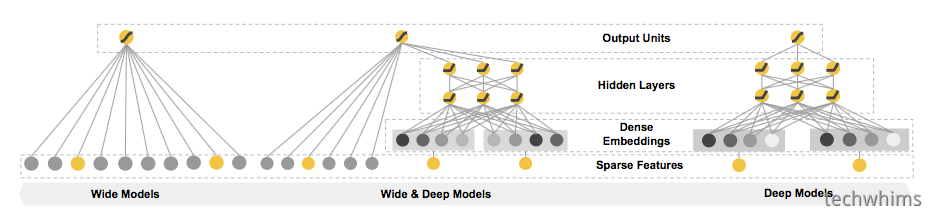
这篇论文(上图model)就是从memorization、generalization做设计和拓展,做了三个方面的贡献,
- wide和deep模型框架联合训练带embedding的前馈神经网络,以及对于稀疏输入的常用推荐系统所使用的带特征转化的线性模型
- 这个推荐系统已经应用于google play
- 这套推荐系统已经在tensorflow上实现了高等级的API,详见 google tensorflow;
(2)推荐系统介绍
如下图大概看一下推荐系统的结构,用户输入query(用户操作、上下文特征),推荐系统返回一个根据点击或者购买等指标优化之后的结果列表,结果列表中每一条数据的出现就是曝光,用户操作(点击等),item展现log输入模型学习器实时学习,更新现有的打分模型。
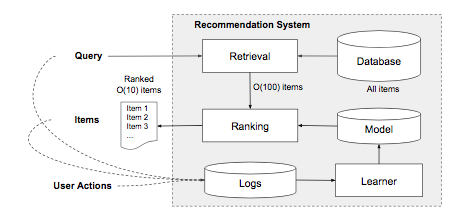
实际上,这个图上可以简单的看出这个推荐系统包含两个部分,retrieval和ranking系统。检索系统可以用机器学习或者人工规则去获取用户的相关的候选集,我们项目之前曾采用的是搜索系统(基于lucene的搜索系统)召回一个千级别数量级的候选集,然后在排序推荐的。ranking系统打分排序经常使用P(y|x),即当用户有x特征的时候y标签出现的概率,x特征包括用户的人口特征、国家、语言、上下文特征(设备、时间特征)、展现特征(app上架时间、历史统计)。这个论文主要使用Wide & Deep learning框架实现ranking模型。
(3)Wide 和Deep learning模型
1> Wide模型
wide模型通常是一个 y = wT x + b的线性模型,是一个高维特征+特征组合的LR,在图1中左边部分,y是预测值,x代表特征向量,w是参数,b是bais。
一个重要的向量积转换定义:
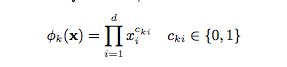 ,其中cki 为一个boolean变量,如果第i个特征是第k个变换ϕk的一部分,那么为1; 否则为0。
,其中cki 为一个boolean变量,如果第i个特征是第k个变换ϕk的一部分,那么为1; 否则为0。
2> Deep learning 模型
Deep 模型是一个前馈神经网络,在图1的右边展示。每一个稀疏、高维的特征首先转为低纬、稠密有值的embedding vector,向量随机初始化,然后训练迭代最小化损失函数,低纬的向量向前传播到神经网络的隐藏层,隐藏层进行如下计算a(l+1) = f(W(l)a(l) + b(l)) ,特征首l表示层数,f表示激活函数,通常采用ReLUs, a(l) , b(l) , and W (l) 是activations、bais,和模型权重。
3> Wide & Deep模型联合训练
论文中模型的训练采用联合训练,即两个模型通过logistic loss function 连接一起进行训练迭代。Wide & Deep模型的联合训练是通过梯度的BP(反向传播)算法、nini-batch SGD优化完成的。论文的实验中,使用的是Follow- the-regularized-leader (FTRL)算法,使用L1正则作为wide部分的优化器,Deep部分使用AdaGrad优化。
联合模型在图1中间展示,LR模型的公式为:
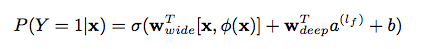
(4) 推荐系统实现
推荐系统实现包括3个部分:数据生成,模型训练,模型serving,如下图所示,
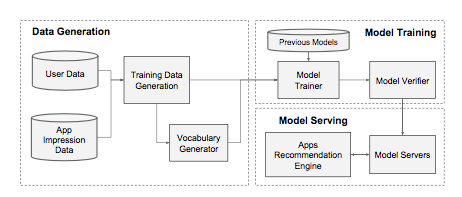
数据生成:用户action数据和app曝光数据作为训练数据;
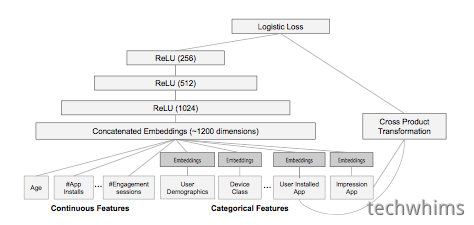
模型训练:如图4中所示方法,在训练期间,输入层接受训练数据和词汇表的输入,一起为一个label生成sparse和dense特征。wide组件包含了用户安装app和曝光app的cross-product tansformation。对于模型的deep组件,会为每个类别型特征学到一个32维的embedding向量。我们将所有embeddings联接起来形成dense features,产生一个接近1200维的dense vector。联接向量接着输入到3个ReLU层,以及最终的logistic输出单元。
 模型serving:论文中说到,作者首先实现了一个warm-starting系统,会使用前一个模型的embeddings和线性模型权重来初始化一个新的模型,在验证之后在线上做AB测试。
模型serving:论文中说到,作者首先实现了一个warm-starting系统,会使用前一个模型的embeddings和线性模型权重来初始化一个新的模型,在验证之后在线上做AB测试。
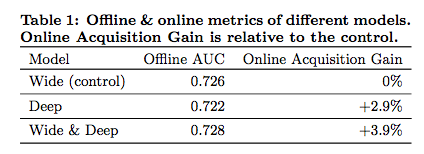
(5)实验效果
可以看到采用这个模型之后,离线AUC提升不多,但是线上效果提升了3.9%,还是可以的
2. 相关知识引入
[1] nonlinear feature 和 feature transformations
我们一般讲到的分类模型(线性分类、LR等等)基本都是线性的(假设数据空间线性可分),但是实际上有时候不是简单的一条线分分开,比如圆形分割线,
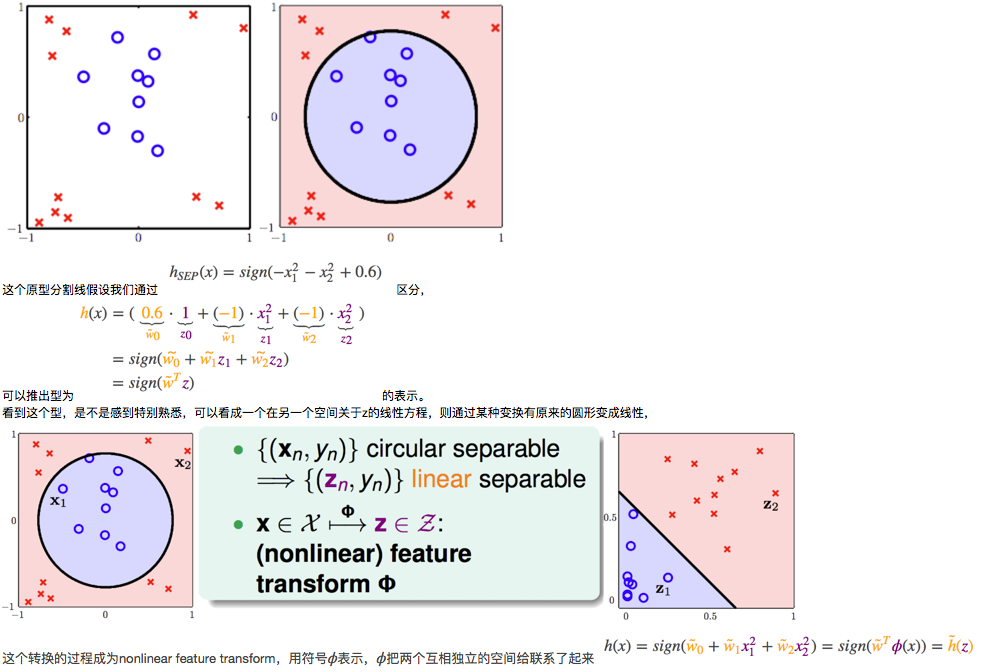
更多内容可以参考(相关链接:http://beader.me/2014/08/30/nonlinear-transformation/),我们一般说的非线性变换,指的是多项式变换(Polynomial Transform)。
用符号ϕQ来表示Q次多项式变换:
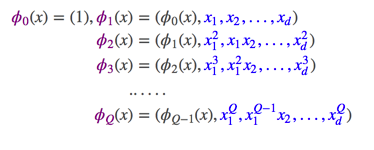
[2] feed-forward neural network
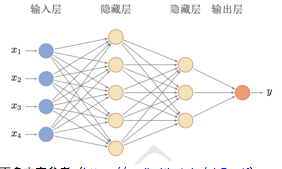
前馈网络中各个神经元按接受信息的先后分为不同的组。每一组可以看 作一个神经层。每一层中的神经元接受前一层神经元的输出,并输出到下一层 神经元。整个网络中的信息是朝一个方向传播,没有反向的信息传播。前馈网 络可以用一个有向无环路图表示。前馈网络可以看作一个函数,通过简单非线 性函数的多次复合,实现输入空间到输出空间的复杂映射。这种网络结构简单, 易于实现。前馈网络包括全连接前馈网络和卷积神经网络等。
前馈神经网络也经常称为多层感知器(Multilayer Perceptron,MLP)。但 多层感知器的叫法并不是十分合理,因为前馈神经网络其实是由多层的logistic 回归模型(连续的非线性函数)组成,而不是由多层的感知器(不连续的非线 性函数)组成,
 更多内容参考(https://nndl.github.io/ch5.pdf)
更多内容参考(https://nndl.github.io/ch5.pdf)
[3] embeded vector
Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
通俗来讲,embeded vector是将词向量化的概念,将一个词映射到一个多维空间向量,比如 苹果 = (0.1,0.6,-0.5…),说到词嵌入,不得不说word2vec,它是谷歌提出一种word embedding 的工具或者算法集合,采用了两种模型(CBOW与skip-gram模型)与两种方法(负采样与层次softmax方法)的组合,比较常见的组合为 skip-gram+负采样方法。
更多相关(词嵌入原理)
[4] ReLU(Rectified Linear Units)激活函数
神经网络中经常使用的激活函数有:Sigmoid系(Logistic-Sigmoid、Tanh-Sigmoid),2001年根据生物学角度提出了新的激活函数,即ReLU,
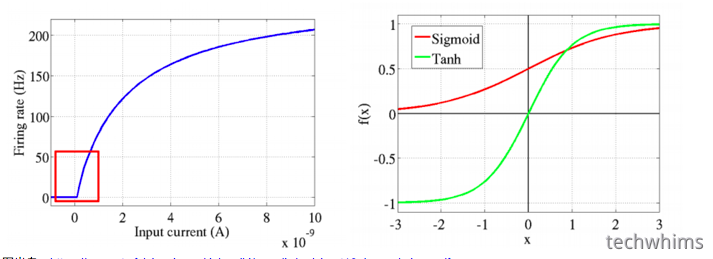 图出自:https://www.utc.fr/~bordesan/dokuwiki/_media/en/glorot10nipsworkshop.pdf
图出自:https://www.utc.fr/~bordesan/dokuwiki/_media/en/glorot10nipsworkshop.pdf
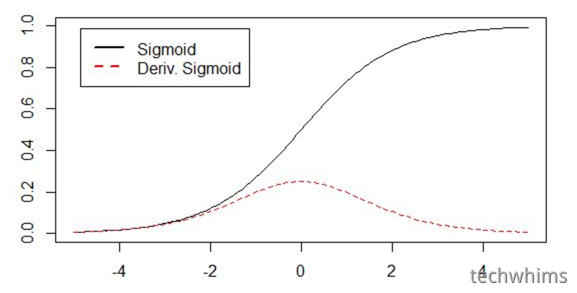
这个模型对比Sigmoid系主要变化有三点:①单侧抑制 ②相对宽阔的兴奋边界 ③稀疏激活性,这三个变化更加准确,
sigmoid系的导数根据图中可以看到,斜率变化速度比较小,梯度更新可能丢失。
ReLU相比sigmoid系的激活函数,有以下的优点:
- 梯度不饱和。梯度计算公式为:x>0则为1,因此在反向传播过程中,减轻了梯度弥散的问题,神经网络前几层的参数也可以很快的更新。
- 计算速度快。正向传播过程中,sigmoid和tanh函数计算激活值时需要计算指数,而Relu函数仅需要设置阈值。如果x<0,f(x)=0,如果x>0,f(x)=x,加快了正向传播的计算速度。
更多参考(http://www.cnblogs.com/neopenx/p/4453161.html)
[5] Follow-the-regularized-leader(FTRL)
由Google的H. Brendan McMahan在2010年提出的[2],作者后来在2011年发表了一篇关于FTRL和AOGD、FOBOS、RDA比较的论文[3],2013年又和Gary Holt, D. Sculley, Michael Young等人发表了一篇关于FTRL工程化实现的论文[4]。如论文[4]的内容所述,FTRL算法融合了RDA算法能产生稀疏模型的特性和SGD算法能产生更有效模型的特性。它在处理诸如LR之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色,
下面这两篇文章不错,移步读一下:http://vividfree.github.io/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2015/12/05/understanding-FTRL-algorithm,http://www.cnblogs.com/EE-NovRain/p/3810737.html
[6] L1正则化
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制,防止某一个参数变化太大影响其他参数的拟合。
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
更多参考(http://blog.csdn.net/zouxy09/article/details/24971995)
[7] AdaGrad自适应学习率调整
这个算法是非常nb的,神经网络中有经典五大超参数:学习率(Leraning Rate)、权值初始化(Weight Initialization)、网络层数(Layers)单层神经元数(Units)、正则惩罚项(Regularizer|Normalization),调整这些参数是非常困难的,Matthew D. Zeiler在2012年提出这个方法,AdaGrad思路基本是借鉴L2 Regularizer,不过此时调节的不是W,是Gradient,
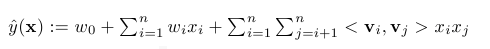 ,AdaGrad过程,是一个递推过程,每次从τ=1,推到τ=t,把沿路的Gradient的平方根,作为Regularizer。分母作为Regularizer项的工作机制如下,
,AdaGrad过程,是一个递推过程,每次从τ=1,推到τ=t,把沿路的Gradient的平方根,作为Regularizer。分母作为Regularizer项的工作机制如下,
训练前期,梯度较小,使得Regularizer项很大,放大梯度。[激励阶段]
训练后期,梯度较大,使得Regularizer项很小,缩小梯度。[惩罚阶段], 由于Regularizer是专门针对Gradient的,所以有利于解决Gradient Vanish/Expoloding问题。当然也有缺点,
初始化W影响初始化梯度,初始化W过大,会导致初始梯度被惩罚得很小。 此时可以人工加大η的值,但过大的η会使得Regularizer过于敏感,调节幅度很大。
训练到中后期,递推路径上累加的梯度平方和越打越多,迅速使得Gradinet被惩罚逼近0,提前结束训练。
更多(http://www.cnblogs.com/neopenx/p/4768388.html、https://zhuanlan.zhihu.com/p/22252270)
论文:http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
[8] factorization machine(FM)隐因子分解机
FM旨在解决是稀疏矩阵下的特征组合问题,上面论文中用户点击采用one-hot编码之后,生成的举证是稀疏的,所以有采用这个方法,举例来说,线性模型有如下式子,
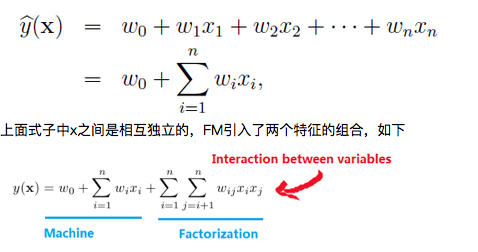 红箭头所指的两个互异特征分量相互作用也加入进去了,用factor来描述特征分量之间的关系,与LR中的交叉组合特征类似。
由于特征矩阵是稀疏的,所以将方程式改写为:
上下两个公式比较,得到W=VT,通过学习隐含主题向量间接来学习W矩阵,减少了学习参数的个数,同时由主成分分析PCA推出VVT能表达W,针对数据不足或者矩阵稀疏时参数过多的问题。
红箭头所指的两个互异特征分量相互作用也加入进去了,用factor来描述特征分量之间的关系,与LR中的交叉组合特征类似。
由于特征矩阵是稀疏的,所以将方程式改写为:
上下两个公式比较,得到W=VT,通过学习隐含主题向量间接来学习W矩阵,减少了学习参数的个数,同时由主成分分析PCA推出VVT能表达W,针对数据不足或者矩阵稀疏时参数过多的问题。
更多参考(https://my.oschina.net/keyven/blog/648747)
论文(http://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
参考文档
(1)论文:Wide & Deep Learning for Recommender Systems
(完)